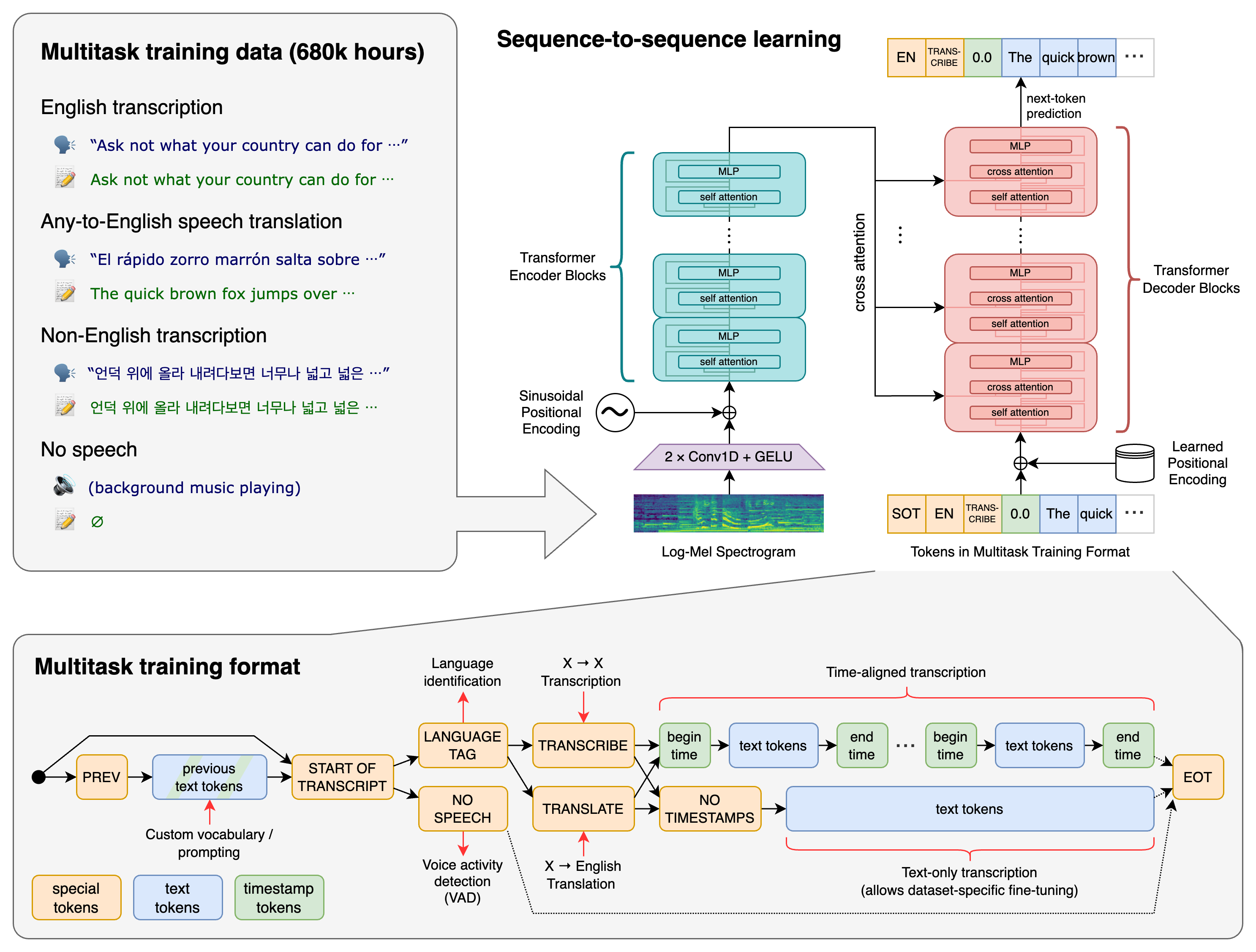
From the figure you can see, the Whisper architecture is a simple end-to-end approach, implemented as an encoder-decoder Transformer. Input audio is split into 30-second chunks, converted into a 80-dimensional log-Mel spectrogram, and then passed into an encoder. Then comes the encoder in form of a convolutional front-end followed by 12 Transformer blocks that processes the entire spectrogram in parallel to produce contextual audio embeddings.
After that, a decoder is trained to predict the corresponding text caption, intermixed with special tokens that direct the single model to perform tasks such as language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
`What is log-Mel?
A log-Mel spectrogram is the standard acoustic representation used as input to most modern ASR systems. The construction pipeline is as follows: raw waveform audio is first segmented into short overlapping frames (e.g., 20–25 ms), then transformed via the Short-Time Fourier Transform (STFT) to obtain a time–frequency representation. This spectrum is then passed through a Mel filterbank, which compresses frequencies according to human auditory perception (denser resolution at low frequencies, coarser at high frequencies). Finally, a logarithmic scaling is applied to the amplitudes, producing the log-Mel spectrogram. The result is a 2D representation (time × frequency bins) that is far more stable and compact than raw waveforms, while preserving perceptually relevant information. This representation is considered the mainstream and default choice in ASR because it strikes an excellent balance between information retention, invariance to noise, and computational efficiency.
Okay, enough for Whisper, let’s take a look at Qwen3-asr (and why we picked that). Surely, it has its own Github repo too: https://github.com/QwenLM/Qwen3-ASR
Released in January 2026 by Alibaba’s Qwen team, Qwen3-ASR is built on the Qwen3-Omni foundation model and represents a significant advancement over Whisper .
As for its architecture, it has three-component design:
- AuT Encoder: A pretrained Audio Transformer that performs 8x downsampling on Fbank features, producing a 12.5Hz token rate
- Projector: Bridges audio encoder representations to the LLM decoder’s embedding space
- LLM Decoder: A full Qwen3 language model (0.6B or 1.7B parameters) that generates text output
From the above we can see that this model is more LLM-ish.
And it is.
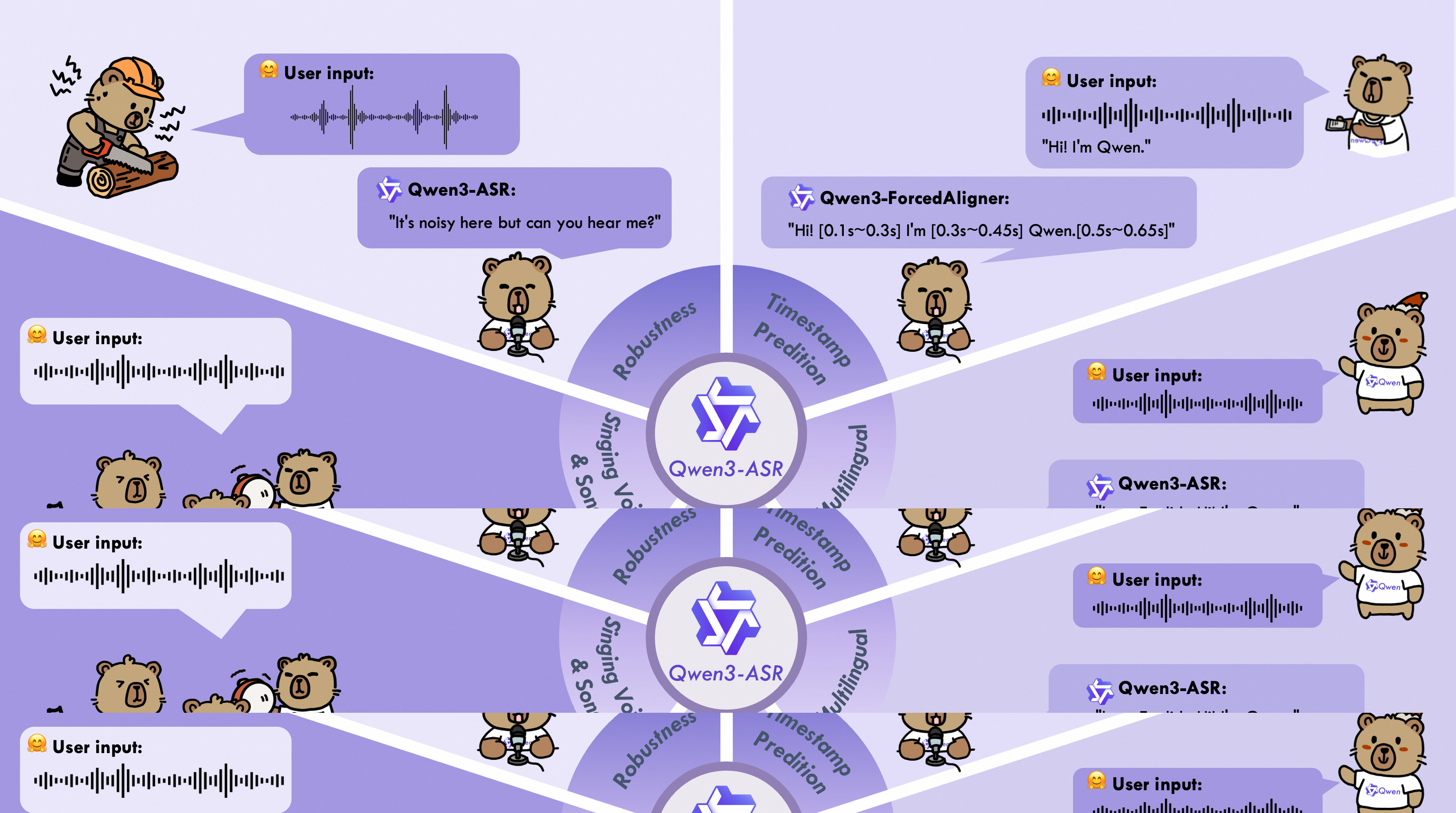
It has dynamic Flash Attention Window. The response speed ranges from 1 to 8 seconds, allowing a single model to handle both streaming (low-latency, real-time) and offline (full-context, higher accuracy) inference without separate weights. It has Built-in Forced Alignment. Qwen3-ForcedAligner-0.6B provides timestamp prediction with 42.9ms average accuracy across 11 languages. It supports up to 10,000 tokens of custom context to improve recognition of domain-specific terms, names, and product phrases, and it has excellent Singing/BGM Handling that achieves <6% WER on solo singing, far outperforming Whisper (Basically it is anti-noise).
We collected some resources, saying the qwen model outperforms Whisper-large-v3 on average across most languages. Its 1.7B model achieves 2000x throughput at 128 concurrency (3x faster than Whisper-large-v3), and more natural language output with better punctuation prediction and sentence segmentation. And it has slightly lower accuracy than Whisper-large-v3 on clean, high-quality English audio, though I think the gap would be felt without precise measurement equipment.
Whisper’s larger variants can be computationally heavy, with latency and memory scaling significantly with model size; it is not inherently optimized for streaming or ultra-low-latency inference . Qwen3-ASR, in contrast, is explicitly engineered for efficiency–accuracy trade-offs, with smaller variants achieving extremely low latency (e.g., ~92 ms TTFT) and high throughput . It also benefits from architectural choices (e.g., GQA, efficient attention) that align with modern inference optimization stacks. This makes Qwen3-ASR more suitable for real-time and large-scale concurrent deployment scenarios.
Splits audio at natural silent pauses to avoid mid-sentence cuts, with configurable target chunk lengths. If you read the above you may find now that this is the major breakthrough, since a fixed 30-chunk is very likely disrupts the transcription quality. It has parallel Processing which uses thread pools to process multiple chunks concurrently. Intelligent Result Aggregation: Automatically reorders segments, removes repetitions, and cleans up hallucinations.
In essence, a younger model whose developers see the huge probress in the realm of LLM would be more likely to outperform its predecessors in the beginning of the era of aritificial intelligence like Whisper, there’s no doubt on that.
Whisper is trained using a fully supervised, large-scale sequence-to-sequence paradigm, where audio is paired with text labels across diverse domains. Its defining characteristic is the sheer scale and heterogeneity of labeled data (680k hours), enabling strong zero-shot generalization without task-specific fine-tuning . In contrast, Qwen3-ASR adopts a more foundation-model-aligned training strategy, leveraging the broader multimodal capabilities of the Qwen3 family (notably Qwen3-Omni) and integrating ASR into a general-purpose audio-language modeling framework . This means Whisper is closer to a “pure ASR system trained at scale,” whereas Qwen3-ASR is an ASR-specialized extension of a general multimodal LLM stack, which influences its downstream flexibility and alignment with LLM-style decoding. That’s why if not controlled propperly, I have sen qwen model outputs improvisation of the true content. Of course, we have taken measures to prevent this from happeing.
Whisper represents the “scaling supervised ASR to the extreme” paradigm, proving that large, diverse labeled datasets can yield highly generalizable models. Qwen3-ASR represents the “LLM-ification of ASR”, where speech recognition becomes a modality within a unified language model framework. This distinction is crucial: Whisper is a specialized model that generalizes broadly, while Qwen3-ASR is a general model that specializes effectively in ASR.
Whisper is trained purely with a cross-entropy loss over autoregressive decoding. The model predicts the next token conditioned on previous tokens and the encoded audio. There is no auxiliary loss (e.g., CTC), no explicit alignment supervision, and no multitask balancing beyond token prompting. This simplicity is a big reason for its stability. Qwen3-ASR tends to incorporate multi-objective training, often combining: autoregressive cross-entropy (like Whisper), alignment-oriented losses (for timestamps or forced alignment), and sometimes CTC-style auxiliary heads (depending on variant). This multi-loss setup improves convergence speed and alignment precision, but introduces more training complexity. In short: Whisper optimizes sequence likelihood, while Qwen3-ASR optimizes a joint objective over recognition + alignment + efficiency.
What is CTC?
A natural next layer beyond both Whisper and Qwen3-ASR is the family of CTC / Transducer hybrid architectures, which try to explicitly solve the alignment and decoding inefficiencies inherent in pure autoregressive models. The core idea of Connectionist Temporal Classification (CTC) is to model the probability of a transcription without requiring explicit frame-level alignment during training. Instead of predicting a strictly ordered sequence, CTC introduces a special blank token and allows multiple possible alignments between audio frames and output tokens, marginalizing over them. This enables parallel training over time steps, which is significantly more efficient than autoregressive decoding. However, pure CTC models lack strong language modeling capacity, often producing less fluent outputs. That is why modern systems (including some Qwen-style variants) use CTC as an auxiliary loss: alongside the main autoregressive cross-entropy loss, the model is also trained to satisfy a CTC objective on encoder outputs.
Both models use encoder–decoder Transformers, but their internal design diverges significantly. Whisper follows a relatively minimalist, classical encoder–decoder Transformer pipeline: log-Mel spectrogram → encoder → autoregressive decoder with task tokens . Its design prioritizes simplicity and robustness. Qwen3-ASR, however, is architecturally hybridized with modern LLM innovations: convolutional front-end (Conv2d downsampling), Transformer encoder with windowed attention, and a Qwen3 decoder featuring GQA, RoPE, RMSNorm, and SwiGLU . This makes Qwen3-ASR closer to LLM-style decoding over audio embeddings, whereas Whisper is a more classical seq2seq ASR system.
Whisper uses a very clean pipeline: audio → log-Mel spectrogram → encoder → decoder that outputs BPE text tokens. The key point is that Whisper does not discretize audio into tokens; audio stays as continuous features, and only text is tokenized. This keeps the modeling objective simple: map continuous acoustic features to discrete text tokens. Qwen3-ASR, by contrast, sits closer to a unified token space philosophy. While it still starts with acoustic features (often log-Mel or learned conv features), its decoder is designed like an LLM, meaning the output token space is tightly aligned with the Qwen tokenizer. In some implementations, this alignment allows easier extension to speech-to-text-to-reasoning pipelines, because the output tokens are natively compatible with downstream LLM modules. The deeper implication: Whisper is speech → text, whereas Qwen3-ASR is closer to speech → language model token stream.
Whisper’s dataset is explicitly documented: ~680,000 hours of multilingual, multitask supervised audio, collected from the web (podcasts, videos, etc.), with about one-third non-English . This dataset is unusually large and diverse for supervised ASR, which explains its robustness. Qwen3-ASR emphasizes dialect coverage and curated multilingual benchmarks, suggesting more targeted data engineering, whereas Whisper emphasizes broad, weakly curated web-scale coverage.
comparisons in other fields
Whisper integrates task control via tokens (e.g., transcription vs translation, timestamps), but timestamp accuracy is relatively coarse and tied to decoder behavior. It is fundamentally autoregressive and not optimized for alignment precision. In contrast, Qwen3-ASR introduces dedicated alignment modeling, including a non-autoregressive forced aligner for high-precision timestamps . This separation of concerns (ASR vs alignment) reflects a more modern system design, where temporal alignment becomes a first-class objective, especially important for subtitle generation and media indexing.
Whisper decoding is fully autoregressive, typically using beam search or greedy decoding. Timestamp prediction is embedded implicitly in the token stream (special timestamp tokens), which can lead to drift, coarse granularity, dependency on decoding heuristics. Qwen3-ASR separates concerns more explicitly: autoregressive decoding for text, non-autoregressive alignment modules for timestamps. This hybrid approach reduces the burden on the decoder. Instead of forcing one model to learn both language and timing, Qwen3-ASR distributes the task across components. The result is typically more stable timestamps and lower latency in alignment-sensitive applications.